HBase数据读写流程 构建高效数据处理与存储支持服务
HBase作为分布式、面向列的开源NoSQL数据库,以其高可靠性、高性能和可扩展性,在当今的大数据生态系统中扮演着至关重要的角色。其核心设计理念源于Google的Bigtable论文,并在Hadoop生态系统中实现了与HDFS的深度集成。理解HBase的数据读写流程,是构建高效、稳定的数据处理与存储支持服务的基础。
一、 HBase核心架构概览
在深入读写流程之前,需简要了解其架构。HBase采用主从(Master-Slave)架构:
- HMaster:负责元数据(如表结构)管理、RegionServer的负载均衡以及故障恢复。
- RegionServer:数据存储和读写请求的实际处理者。每个RegionServer管理多个Region(数据分片)。
- Region:表数据的水平分区,是负载均衡和分布式存储的基本单位。随着数据增长,Region会分裂。
- ZooKeeper:作为协调服务,负责维护集群状态(如活跃的HMaster、RegionServer列表)、元数据入口以及分布式锁。
- HDFS:作为底层持久化存储,提供高可靠的数据存储支持。
二、 数据写入流程详解
HBase的写入操作(如Put)遵循一个高效且保证一致性的路径,旨在实现快速的随机写入。
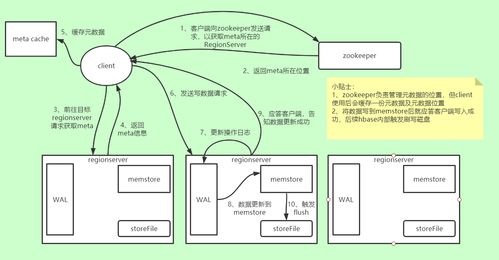
- 客户端发起请求:客户端(Client)首先从ZooKeeper获取
hbase:meta表的位置信息(该表记录了所有用户表Region的分布信息)。
- 定位目标Region:客户端查询
hbase:meta表,确定将要写入的行键(RowKey)所属的Region及其所在的RegionServer。此信息会被缓存以加速后续请求。
- 发送写请求至RegionServer:客户端将写请求(包含行键、列族、列限定符、值、时间戳等)直接发送给目标RegionServer。
- RegionServer处理写入:
- 写入WAL(Write-Ahead Log):为保证数据持久性,防止内存数据丢失,首先将数据变更顺序追加写入到HDFS上的WAL文件中。这是“先写日志”原则的体现,是恢复机制的关键。
- 写入MemStore:数据被写入到对应Region中特定列族(Column Family)的内存缓冲区——MemStore中。MemStore中的数据按行键排序存储。写入到此即对客户端返回成功,实现了低延迟。
- MemStore刷写(Flush):当MemStore的大小达到阈值(
hbase.hregion.memstore.flush.size),或整个RegionServer的MemStore总和达到一定比例时,系统会异步地将MemStore中的数据顺序写入HDFS,生成一个新的存储文件——HFile。刷写完成后,对应的MemStore被清空,并在WAL中做一个标记。此过程将随机写转换为顺序写,极大提升了HDFS的写入效率。
- 后台合并与压缩:随着刷写次数增多,会产生大量小文件(HFile)。HBase会定期执行Minor Compaction(合并数个相邻的较小HFile)和Major Compaction(合并一个Region内一个列族的所有HFile,并清理已删除或过期的数据),以减少文件数量、提升读性能并回收空间。
三、 数据读取流程详解
HBase的读取操作(如Get、Scan)旨在从多级存储结构中高效定位数据。
- 客户端定位Region:与写入流程类似,客户端首先通过ZooKeeper和
hbase:meta表定位目标行键或扫描范围所在的RegionServer。
- 发送读请求至RegionServer:将请求发送给相应的RegionServer。
- RegionServer并发读取:RegionServer收到请求后,会从多个可能的数据源中并行查找数据,并按照时间戳等规则合并结果。读取顺序遵循一个层次结构(可视为一个“读取合并”过程):
- Block Cache:首先检查读缓存。Block Cache缓存的是从HFile中读取的数据块(Block),采用LRU策略。适合频繁访问的热点数据。
- MemStore:然后查询对应列族的MemStore(其中包含尚未刷写到磁盘的最新数据)。
- HFile(磁盘):在HDFS上的HFile文件中进行查找。为了加速,HBase使用了布隆过滤器(Bloom Filter)来快速判断某个行键是否存在于一个特定的HFile中,避免了不必要的磁盘IO。索引(每个HFile有行键索引)和数据块(Block)的本地化(Data Locality)也优化了读取速度。
- 结果合并与返回:将从Block Cache、MemStore和多个HFile中读取到的数据(可能包含同一单元格的多个版本)进行合并,根据时间戳或版本数等条件筛选出最终结果,返回给客户端。
四、 对数据处理与存储支持服务的启示
深入理解HBase读写流程,对于设计和运维数据处理与存储服务具有重要指导意义:
- 高性能设计:
- 写优化:通过WAL+MemStore模型,将随机写转化为内存写和顺序磁盘写,支撑高吞吐写入。设计RowKey时应考虑均匀分布,避免写入热点。
- 读优化:多层缓存(Block Cache, MemStore)和高效索引(布隆过滤器、行键索引)保障了随机读性能。根据业务特点调整缓存大小和块大小至关重要。
- 高可靠性与一致性保障:WAL机制确保了即使在RegionServer宕机后,未刷写的数据也能恢复。HDFS的多副本机制为数据提供了底层存储容错。
- 可扩展性支撑:Region自动分裂和HMaster的负载均衡使得集群可以近乎线性地通过增加机器来扩展存储容量和吞吐量。
- 服务运维关键点:
- 监控MemStore刷写频率、Compaction压力,防止写入阻塞。
- 合理设置Major Compaction周期,平衡读性能提升与IO开销。
- 确保RegionServer与HDFS DataNode的“数据本地化”,减少网络传输。
- 根据访问模式(读多写少/写多读少)优化Block Cache与MemStore的配置。
结论
HBase的数据读写流程是其高性能、高可靠特性的工程化体现。从客户端的路由寻址,到服务端的WAL持久化、内存缓冲、多级存储与缓存检索,这一整套精密的协作机制,共同构成了一个能够处理海量数据、支持随机实时访问的强大存储引擎。在构建企业级的数据处理与存储平台时,充分理解和利用这些机制,是确保服务能够稳定、高效支撑上层业务应用(如实时监控、用户画像、消息存储等)的关键所在。
如若转载,请注明出处:http://www.520hbwl.com/product/68.html
更新时间:2026-02-25 07:31:50