TiDB原理与实战 数据处理和存储支持服务详解
TiDB作为新一代开源分布式数据库,通过独特的架构设计实现了大数据存储与处理的高效支持。在实战应用中,其数据处理和存储支持服务的核心原理和实现机制至关重要,本文将从原理和实战角度深入解析。
一、TiDB架构原理概述
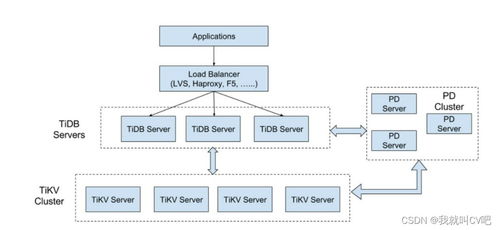
TiDB采用分层架构,包括无状态的计算层(TiDB Server)、分布式存储层(TiKV)和集群管理组件(PD)。计算层负责SQL解析与优化,存储层基于Raft协议保证数据强一致性,PD组件负责元数据管理与负载均衡。这种解耦设计使得TiDB具备水平扩展能力,可支撑PB级数据规模。
二、数据处理机制原理与实战
- SQL处理流程:TiDB计算层首先解析SQL语句,生成逻辑执行计划,再结合统计信息优化为物理执行计划。实践中,可通过EXPLAIN语句分析执行计划,针对慢查询进行索引优化或SQL重写。
- 分布式事务处理:TiDB采用乐观锁机制,通过两阶段提交(2PC)保证ACID特性。实战中需注意热点更新问题,可通过分片键设计或批量操作优化事务性能。
- 数据分区与分片:TiKV将数据按Range划分为多个Region,每个Region默认96MB。实际部署时,应预估数据量合理配置Region大小,避免频繁分裂影响性能。
三、存储支持服务原理与实战
- 多副本与高可用:TiKV基于Raft协议实现数据多副本(默认3副本),任一节点故障不影响服务可用性。实战中需确保网络延迟稳定,跨机房部署时建议配置5副本以提高容灾能力。
- 存储引擎优化:TiKV底层使用RocksDB作为存储引擎,采用LSM-Tree结构优化写性能。实际运维中需监控Compaction压力,适时调整压缩策略避免写放大。
- 混合负载支持:TiDB通过TiFlash提供列式存储,支持实时分析查询。实战中可通过设置副本优先级,将OLAP查询路由至TiFlash,实现HTAP混合负载隔离。
四、运维实战要点
- 监控告警:通过TiDB Dashboard和Prometheus监控集群健康度,重点关注QPS、延迟、Region分布等指标。
- 备份恢复:使用BR(Backup & Restore)工具进行全量与增量备份,建议结合定时任务实现自动化灾备。
- 版本升级:TiDB支持在线滚动升级,但需提前测试业务兼容性,建议在业务低峰期执行。
TiDB通过创新的分布式架构,为大数据场景提供了完善的数据处理和存储支持服务。在实战中,深入理解其原理并结合具体业务特点进行调优,可充分发挥其高可用、强一致和弹性扩展的优势。
如若转载,请注明出处:http://www.520hbwl.com/product/24.html
更新时间:2025-11-29 13:57:44